Redis入门(一)
什么是Redis
Redis是一款内存高速缓存数据库。Redis全称为:Remote Dictionary Server(远程数据服务),使用C语言编写,Redis是一个key-value存储系统(键值存储系统),支持丰富的数据类型,如:String、list、set、zset、hash。
Redis是一种支持key-value等多种数据结构的存储系统。可用于缓存,事件发布或订阅,高速队列等场景。支持网络,提供字符串,哈希,列表,队列,集合结构直接存取,基于内存,可持久化。
为什么要使用Redis
一个产品的使用场景肯定是需要根据产品的特性,先列举一下Redis的特点:
- 读写性能优异
- Redis能读的速度是110000次/s,写的速度是81000次/s
- 数据类型丰富
- Redis支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作。
- 原子性
- Redis的所有操作都是原子性的,同时Redis还支持对几个操作全并后的原子性执行。
- 丰富的特性
- Redis支持 publish/subscribe, 通知, key 过期等特性。
- 持久化
- Redis支持RDB, AOF等持久化方式
- 发布订阅
- Redis支持发布/订阅模式
- 分布式
- Redis Cluster
Redis的使用场景
热点数据的缓存
缓存是Redis最常见的应用场景,之所有这么使用,主要是因为Redis读写性能优异。而且逐渐有取代 memcached,成为首选服务端缓存的组件。而且,Redis内部是支持事务的,在使用时候能有效保证数据的一致性。
作为缓存使用时,一般有两种方式保存数据:
- 读取前,先去读Redis,如果没有数据,读取数据库,将数据拉入Redis。
- 插入数据时,同时写入Redis。
方案一:实施起来简单,但是有两个需要注意的地方:
- 避免缓存击穿。(数据库没有就需要命中的数据,导致Redis一直没有数据,而一直命中数据库。)
- 数据的实时性相对会差一点。
方案二:数据实时性强,但是开发时不便于统一处理。
当然,两种方式根据实际情况来适用。如:方案一适用于对于数据实时性要求不是特别高的场景。方案二适用于字典表、数据量不大的数据存储。
限时业务的运用
redis中可以使用expire命令设置一个键的生存时间,到时间后redis会删除它。利用这一特性可以运用在限时的优惠活动信息、手机验证码等业务场景。
计数器相关问题
redis由于incrby命令可以实现原子性的递增,所以可以运用于高并发的秒杀活动、分布式序列号的生成、具体业务还体现在比如限制一个手机号发多少条短信、一个接口一分钟限制多少请求、一个接口一天限制调用多少次等等。
分布式锁
这个主要利用redis的setnx命令进行,setnx:"set if not exists"就是如果不存在则成功设置缓存同时返回1,否则返回0 ,这个特性在很多后台中都有所运用,因为我们服务器是集群的,定时任务可能在两台机器上都会运行,所以在定时任务中首先 通过setnx设置一个lock, 如果成功设置则执行,如果没有成功设置,则表明该定时任务已执行。 当然结合具体业务,我们可以给这个lock加一个过期时间,比如说30分钟执行一次的定时任务,那么这个过期时间设置为小于30分钟的一个时间就可以,这个与定时任务的周期以及定时任务执行消耗时间相关。
在分布式锁的场景中,主要用在比如秒杀系统等。
延时操作
比如在订单生产后我们占用了库存,10分钟后去检验用户是否真正购买,如果没有购买将该单据设置无效,同时还原库存。 由于redis自2.8.0之后版本提供Keyspace Notifications功能,允许客户订阅Pub/Sub频道,以便以某种方式接收影响Redis数据集的事件。 所以我们对于上面的需求就可以用以下解决方案,我们在订单生产时,设置一个key,同时设置10分钟后过期, 我们在后台实现一个监听器,监听key的实效,监听到key失效时将后续逻辑加上。
当然我们也可以利用rabbitmq、activemq等消息中间件的延迟队列服务实现该需求。
排行榜相关问题
关系型数据库在排行榜方面查询速度普遍偏慢,所以可以借助redis的SortedSet进行热点数据的排序。
比如点赞排行榜,做一个SortedSet, 然后以用户的openid作为上面的username, 以用户的点赞数作为上面的score, 然后针对每个用户做一个hash, 通过zrangebyscore就可以按照点赞数获取排行榜,然后再根据username获取用户的hash信息,这个当时在实际运用中性能体验也蛮不错的。
点赞、好友等相互关系的存储
Redis 利用集合的一些命令,比如求交集、并集、差集等。
在微博应用中,每个用户关注的人存在一个集合中,就很容易实现求两个人的共同好友功能。
简单队列
由于Redis有 list push 和 list pop 这样的命令,所以能够很方便的执行队列操作。
数据类型
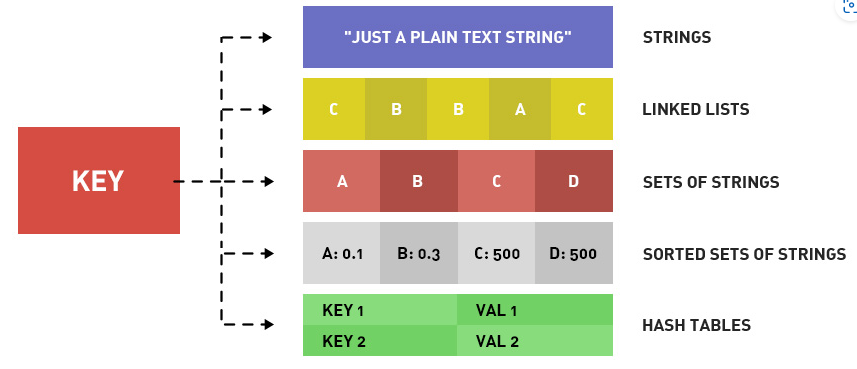
Redis所有的 key(键)都是字符串。我们在谈基础数据结构时,讨论的是存储值的数据类型,主要包括常见的5种数据类型,分别是:String、List、Set、Zset、Hash
Redis数据结构简介
Redis基础文章非常多,关于基础数据结构类型,我推荐你先看下官方网站内容 (opens new window),然后再看下面的小结。
首先对redis来说,所有的key(键)都是字符串。我们在谈基础数据结构时,讨论的是存储值的数据类型,主要包括常见的5种数据类型,分别是:String、List、Set、Zset、Hash。
| 结构类型 | 结构存储的值 | 结构的读写能力 |
|---|---|---|
| String字符串 | 可以是字符串、整数或浮点数 | 对整个字符串或字符串的一部分进行操作;对整数或浮点数进行自增或自减操作; |
| List列表 | 一个链表,链表上的每个节点都包含一个字符串 | 对链表的两端进行push和pop操作,读取单个或多个元素;根据值查找或删除元素; |
| Set集合 | 包含字符串的无序集合 | 字符串的集合,包含基础的方法有看是否存在添加、获取、删除;还包含计算交集、并集、差集等 |
| Hash散列 | 包含键值对的无序散列表 | 包含方法有添加、获取、删除单个元素 |
| Zset有序集合 | 和散列一样,用于存储键值对 | 字符串成员与浮点数分数之间的有序映射;元素的排列顺序由分数的大小决定;包含方法有添加、获取、删除单个元素以及根据分值范围或成员来获取元素 |
基础数据结构详解
String字符串
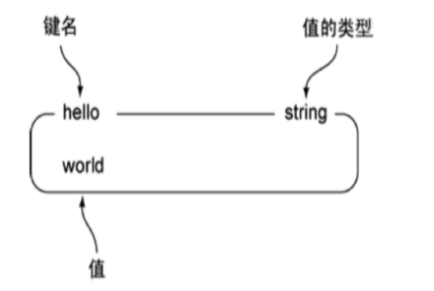
String是redis中最基本的数据类型,一个key对应一个value。
String类型是二进制安全的,意思是 redis 的 string 可以包含任何数据。如数字,字符串,jpg图片或者序列化的对象。
| 命令 | 简述 | 使用 |
|---|---|---|
| GET | 获取存储在给定键中的值 | GET name |
| SET | 设置存储在给定键中的值 | SET name value |
| DEL | 删除存储在给定键中的值 | DEL name |
| INCR | 将键存储的值加1 | INCR key |
| DECR | 将键存储的值减1 | DECR key |
| INCRBY | 将键存储的值加上整数 | INCRBY key amount |
| DECRBY | 将键存储的值减去整数 | DECRBY key amount |
127.0.0.1:6379> set hello world
OK
127.0.0.1:6379> get hello
"world"
127.0.0.1:6379> del hello
(integer) 1
127.0.0.1:6379> get hello
(nil)
127.0.0.1:6379> set counter 2
OK
127.0.0.1:6379> get counter
"2"
127.0.0.1:6379> incr counter
(integer) 3
127.0.0.1:6379> get counter
"3"
127.0.0.1:6379> incrby counter 100
(integer) 103
127.0.0.1:6379> get counter
"103"
127.0.0.1:6379> decr counter
(integer) 102
127.0.0.1:6379> get counter
"102"实战场景:
- 缓存: 经典使用场景,把常用信息,字符串,图片或者视频等信息放到redis中,redis作为缓存层,mysql做持久化层,降低mysql的读写压力。
- 计数器:redis是单线程模型,一个命令执行完才会执行下一个,同时数据可以一步落地到其他的数据源。
- session:常见方案spring session + redis实现session共享。
List列表
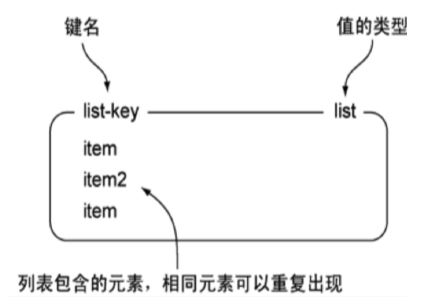
Redis中的List其实就是链表(Redis用双端链表实现List)
使用List结构,我们可以轻松地实现最新消息排队功能(比如新浪微博的TimeLine)。List的另一个应用就是消息队列,可以利用List的 PUSH 操作,将任务存放在List中,然后工作线程再用 POP 操作将任务取出进行执行。
| 命令 | 简述 | 使用 |
|---|---|---|
| RPUSH | 将给定值推入到列表右端 | RPUSH key value |
| LPUSH | 将给定值推入到列表左端 | LPUSH key value |
| RPOP | 从列表的右端弹出一个值,并返回被弹出的值 | RPOP key |
| LPOP | 从列表的左端弹出一个值,并返回被弹出的值 | LPOP key |
| LRANGE | 获取列表在给定范围上的所有值 | LRANGE key 0 -1 |
| LINDEX | 通过索引获取列表中的元素。你也可以使用负数下标,以 -1 表示列表的最后一个元素, -2 表示列表的倒数第二个元素,以此类推 | LINDEX key index |
使用技巧:
- lpush+lpop=Stack(栈)
- lpush+rpop=Queue(队列)
- lpush+ltrim=Capped Collection(有限集合)
- lpush+brpop=Message Queue(消息队列)
127.0.0.1:6379> lpush mylist 1 2 ll ls mem
(integer) 5
127.0.0.1:6379> lrange mylist 0 -1
1) "mem"
2) "ls"
3) "ll"
4) "2"
5) "1"
127.0.0.1:6379> lindex mylist -1
"1"
127.0.0.1:6379> lindex mylist 10 # index不在 mylist 的区间范围内
(nil)实战场景:
- 微博TimeLine: 有人发布微博,用lpush加入时间轴,展示新的列表信息。
- 消息队列
Set集合
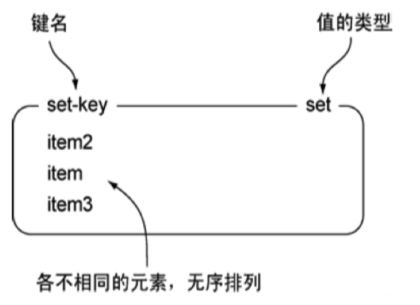
Redis 的 Set 是 String 类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据
Redis 中集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)
| 命令 | 简述 | 使用 |
|---|---|---|
| SADD | 向集合添加一个或多个成员 | SADD key value |
| SCARD | 获取集合的成员数 | SCARD key |
| SMEMBERS | 返回集合中的所有成员 | SMEMBERS key member |
| SISMEMBER | 判断 member 元素是否是集合 key 的成员 | SISMEMBER key member |
其它一些集合操作,请参考这里 https://www.runoob.com/redis/redis-sets.html
127.0.0.1:6379> sadd myset hao hao1 xiaohao hao
(integer) 3
127.0.0.1:6379> smembers myset
1) "xiaohao"
2) "hao1"
3) "hao"
127.0.0.1:6379> sismember myset hao
(integer) 1实战场景:
-
标签(tag),给用户添加标签,或者用户给消息添加标签,这样有同一标签或者类似标签的可以给推荐关注的事或者关注的人
- 点赞,或点踩,收藏等,可以放到set中实现
Hash散列
Redis hash 是一个 string 类型的 field(字段) 和 value(值) 的映射表,hash 特别适合用于存储对象。
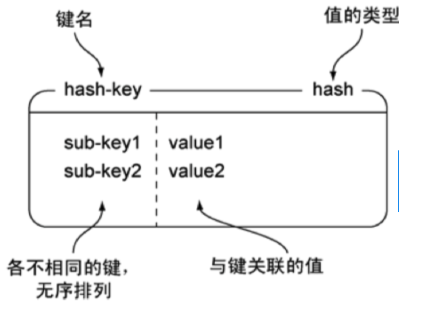
| 命令 | 简述 | 使用 |
|---|---|---|
| HSET | 添加键值对 | HSET hash-key sub-key1 value1 |
| HGET | 获取指定散列键的值 | HGET hash-key key1 |
| HGETALL | 获取散列中包含的所有键值对 | HGETALL hash-key |
| HDEL | 如果给定键存在于散列中,那么就移除这个键 | HDEL hash-key sub-key1 |
127.0.0.1:6379> hset user name1 hao
(integer) 1
127.0.0.1:6379> hset user email1 hao@163.com
(integer) 1
127.0.0.1:6379> hgetall user
1) "name1"
2) "hao"
3) "email1"
4) "hao@163.com"
127.0.0.1:6379> hget user user
(nil)
127.0.0.1:6379> hget user name1
"hao"
127.0.0.1:6379> hset user name2 xiaohao
(integer) 1
127.0.0.1:6379> hset user email2 xiaohao@163.com
(integer) 1
127.0.0.1:6379> hgetall user
1) "name1"
2) "hao"
3) "email1"
4) "hao@163.com"
5) "name2"
6) "xiaohao"
7) "email2"
8) "xiaohao@163.com"实战场景:
- 缓存: 能直观,相比string更节省空间,的维护缓存信息,如用户信息,视频信息等。
Zset有序集合
Redis 有序集合和集合一样也是 string 类型元素的集合,且不允许重复的成员。不同的是每个元素都会关联一个 double 类型的分数。redis 正是通过分数来为集合中的成员进行从小到大的排序。
有序集合的成员是唯一的, 但分数(score)却可以重复。有序集合是通过两种数据结构实现:
- 压缩列表(ziplist): ziplist是为了提高存储效率而设计的一种特殊编码的双向链表。它可以存储字符串或者整数,存储整数时是采用整数的二进制而不是字符串形式存储。它能在O(1)的时间复杂度下完成list两端的push和pop操作。但是因为每次操作都需要重新分配ziplist的内存,所以实际复杂度和ziplist的内存使用量相关
- 跳跃表(zSkiplist): 跳跃表的性能可以保证在查找,删除,添加等操作的时候在对数期望时间内完成,这个性能是可以和平衡树来相比较的,而且在实现方面比平衡树要优雅,这是采用跳跃表的主要原因。跳跃表的复杂度是O(log(n))。
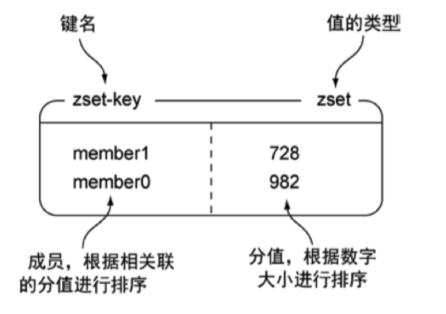
| 命令 | 简述 | 使用 |
|---|---|---|
| ZADD | 将一个带有给定分值的成员添加到有序集合里面 | ZADD zset-key 178 member1 |
| ZRANGE | 根据元素在有序集合中所处的位置,从有序集合中获取多个元素 | ZRANGE zset-key 0-1 withccores |
| ZREM | 如果给定元素成员存在于有序集合中,那么就移除这个元素 | ZREM zset-key member1 |
127.0.0.1:6379> zadd myscoreset 100 hao 90 xiaohao
(integer) 2
127.0.0.1:6379> ZRANGE myscoreset 0 -1
1) "xiaohao"
2) "hao"
127.0.0.1:6379> ZSCORE myscoreset hao
"100"实战场景:
- 排行榜:有序集合经典使用场景。例如小说视频等网站需要对用户上传的小说视频做排行榜,榜单可以按照用户关注数,更新时间,字数等打分,做排行。
PS. Q: How do I delete everything in Redis?
A: With redis-cli:
FLUSHALL Remove all keys from all databases
FLUSHDB Remove all keys from the current database
SCRIPT FLUSH Remove all the scripts from the script cache.
另外默认情况下 Redis 会每隔一段时间做一次快照保存在本地磁盘上
本文转载自:链接:Redis入门 - 数据类型:5种基础数据类型详解 | Java 全栈知识体系
著作权归https://pdai.tech所有。