用Python粗糙地实现贝叶斯推理之β分布
前言
本文给出的代码只是为了好玩,没有什么质量可言,遵循
Make it run , Make it right , Make it fast
先让它跑起来,至于代码美观和效率则不考虑,反正也没人用,自娱自乐
将概率的概率作为先验概率
在贝叶斯推理中,有先验概率,条件概率,后验概率。 具体的定义这里不再详述,之前的文章也有提及。为了便于理解“将概率的概率作为先验概率”,这里从一个示例讲起,选自《小岛宽之. 统计学关我什么事:生活中的极简统计学》
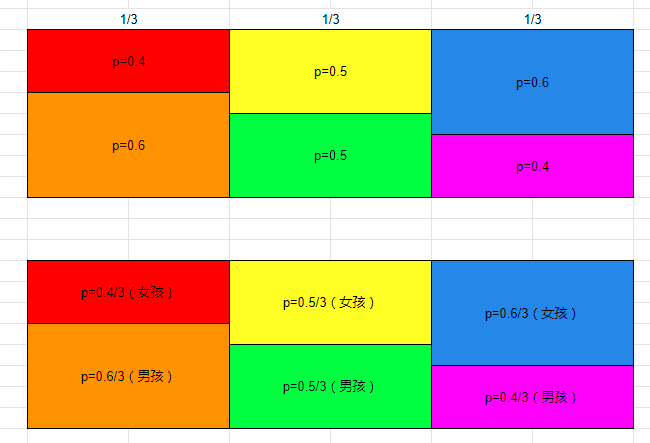
一对夫妇第一胎生了女孩,请问第二胎是女孩的概率?
这对夫妇生女孩的概率为P,假设P=0.4,P=0.5,P=0.6,即这对夫妇生女孩的概率是0.4,0.5,0.6 。 概率的概率 就是这对夫妇生女孩的概率是0.4的概率,这对夫妇生女孩的概率是0.5的概率,这对夫妇生女孩的概率是0.6的概率。 把概率的概率作为先验概率,由于我们不知道这对夫妇到底是哪一种类型,假设每种的概率都相同,当然,先验概率就是可以随便给出的,这里都取1/3。
因为第一胎是女孩,所以
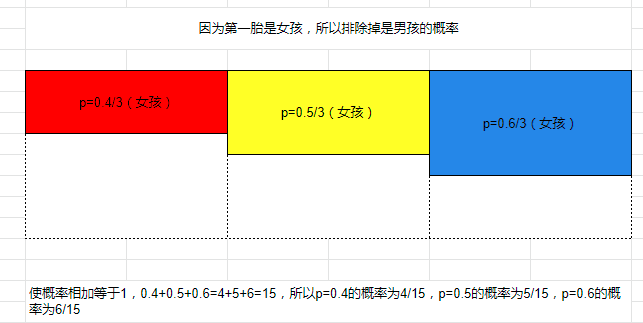
这里主要介绍下将概率的概率作为先验概率,为下面的内容做个基础准备。
更具体的概率
上面的示例中,这对夫妇生女孩的概率只有三种情况【0.4,0.5,0.6】,但是实际生活中有无穷种可能,从0到1,是连续的。为了方便计算,这里采用从0-100(0,1,2,...,98,99,100),即
这对夫妇生女孩的概率是0%
这对夫妇生女孩的概率是1%
这对夫妇生女孩的概率是2%
...
这对夫妇生女孩的概率是98%
这对夫妇生女孩的概率是99%
这对夫妇生女孩的概率是100%
每种情况的概率相等,也就是从0到100的概率相等,共101种情况,概率是100(百分制),那么每种概率就是100/101,先验概率就是(100/101)
类比刚才只有三种情况的做法,画出矩形表格,这里就不画了,然后出生的结果是女孩,去掉是男孩的部分,剩下的面积要符合总概率等于100的情况,计算出每个概率所对应的概率,就是后验概率。
不忍直视的Python代码
代码写得很烂,先让它跑起来,以后再优化下(如果可能的话,呵呵!)
# -*- coding: UTF-8 -*-
import numpy
'''
自定义变量
init_prior_pr 初始先验概率
prior_pr 先验概率
posterior_pr 后验概率
result 结果集 (0代表True,1代表False)
x_pr X事件概率
y_pr Y事件概率 (X事件概率 + Y事件概率 = 1)
'''
def beta_pr(result):
# 先设置初始先验概率为空列表
init_prior_pr = []
# 假设所有概率都相等,通过循环得到初始先验概率列表
ii = 100/101
count = 0
while (count < 101):
init_prior_pr.append(ii)
count = count + 1
# 初始化X事件的概率
x_pr = list(range(0, 101)) # 生成 0-100 数字
# 根据X事件生成Y事件
y_pr = []
count = 0
while (count < 101):
tmp = 100 - x_pr[count]
y_pr.append(tmp)
count = count + 1
# 将初始先验概率赋值给一个临时变量
prpr = init_prior_pr
# 开始处理导入的结果集
for res in result:
# 初始化各个值
x_sum = 0
y_sum = 0
# 从临时变量中得到先验概率
prior_pr = prpr
# 计算各个事件的总概率
for elem in range(101):
x_sum = x_sum + prior_pr[elem] * x_pr[elem]
y_sum = y_sum + prior_pr[elem] * y_pr[elem]
# 处理事件
if res == 0:
# 观察到X事件的后验概率
posterior_pr = []
for elem1 in range(101):
pmt = prior_pr[elem1] * x_pr[elem1] / x_sum
posterior_pr.append(pmt) # 生成后验概率列表
# 将后验概率赋值给临时变量,在下一轮循环中当作先验概率
prpr = posterior_pr
# 计算X事件的各个概率的概率,最后计算出X事件的期望值
x_expect = 0
for elem3 in range(101):
x_expect = x_expect + x_pr[elem3] * posterior_pr[elem3] # 计算期望值
x_expect = x_expect
x_expect = round(x_expect, 0)
# print (x_expect)
elif res == 1:
# 观察到Y事件的后验概率
posterior_pr = []
for elem2 in range(101):
mtp = prior_pr[elem2] * y_pr[elem2] / y_sum
posterior_pr.append(mtp) # 生成后验概率列表
# 将后验概率赋值给临时变量,在下一轮循环中当作先验概率
prpr = posterior_pr
# 计算X事件的各个概率的概率,最后计算出X事件的期望值
x_expect = 0
for elem4 in range(101):
x_expect = x_expect + x_pr[elem4] * posterior_pr[elem4] # 计算期望值
x_expect = x_expect
x_expect = round(x_expect, 0)
# print (x_expect)
return(x_expect)这里给出的结果是期望,也就是每个概率再乘以它们各自的概率,关于什么是期望,请直接参考维基百科关于期望的条目
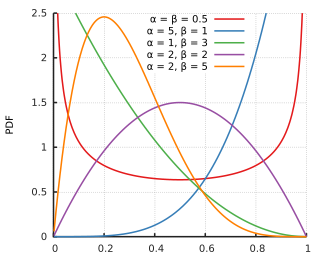
最后,关于β分布
如果这对夫妻生女孩的概率是从0到100连续的,那么概率的概率也连续的,这两个数值在一个直角坐标系的第一象限形成一个曲线的图像,就是β分布函数。
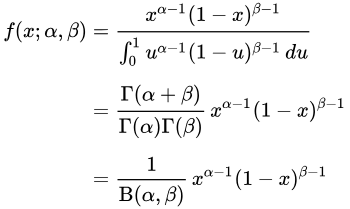
这个函数的期望:
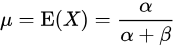
上述公式计算的期望结果和上面的Python代码计算结果是一样的
当这对夫妻第一胎是女孩,那么第二胎还是女孩的概率期望是:
Python代码
... #省略上述代码
sex = [0] # 女孩为0,男孩为1
print (beta_pr(sex))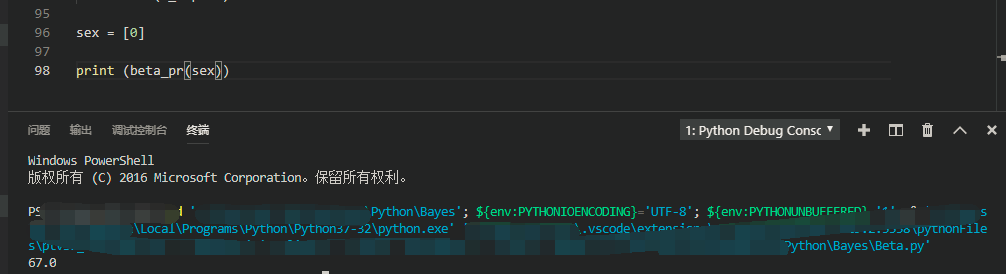
β分布函数
当概率的概率都是相等的时候,那么β分布函数是一条平行于X轴的线段,Y轴的具体数值不管取决于参数B的大小
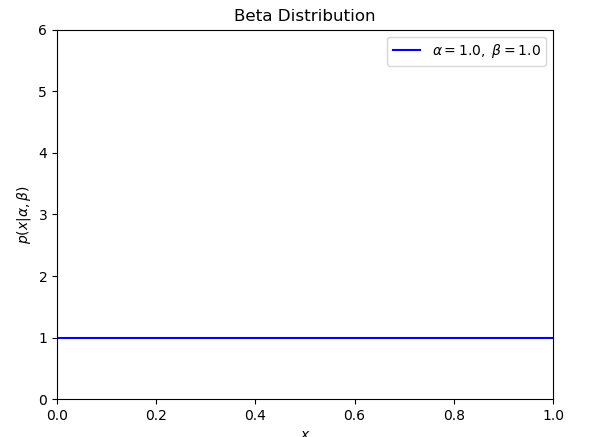
所以这里的先决条件是 α = 1,β =1 当第一胎是女孩,第二胎还是女孩的概率期望
α = 2 (因为第一胎是女孩,所以可以理解为α+1了)
β = 1 (同理,如果是男孩那么β+1)
期望等于 E = α/(α+β)=2/3=0.67(近似值)
继续增加
sex = [0,1,1] (女孩,男孩,男孩)
则
α = 2,β = 3
计算结果是相同的,这里就不写了
如果想继续了解β分布,推荐阅读知乎上的一篇问答 如何通俗理解 beta 分布?
全文完
本文参考:
《小岛宽之. 统计学关我什么事:生活中的极简统计学》
维基百科
Python 手册
感谢自由的互联网,让我一个毫无基础的人能学到这些知识。